HTTP 历史
史前年代
20 世纪 60 年代,美国国防部高等研究计划署(ARPA)建立了 ARPA 网,它有四个分布在各地的节点,被认为是如今互联网的“始祖”
70 年代,基于对 ARPA 网的实践和思考,研究人员发明出了著名的 TCP/IP 协议。并在 80 年代中期进入了 UNIX 系统内核,促使更多的计算机接入了互联网
创世纪
1989 年,任职于欧洲核子研究中心(CERN)的蒂姆·博纳斯·李发表了一篇论文,提出了在互联网上构建超链接文档系统的构想。这篇论文中他确立了三项关键技术
- URI:即统一资源标识符,作为互联网上资源的唯一身份;
- HTML:即超文本标记语言,描述超文本文档;
- HTTP:即超文本传输协议,用来传输超文本;
基于它们,就可以把超文本系统完美地运行在互联网上,让各地的人们能够自由地共享信息,蒂姆把这个系统称为“万维网”(World Wide Web),也就是我们现在所熟知的 Web
HTTP/0.9
它只支持纯文本格式,以及只允许“GET”请求,并且在相应请求之后立即关闭连接,功能有限
“把简单的系统变复杂”,要比“把复杂的系统变简单”容易的多
HTTP/1.0
1993 年,NCSA(美国国家超级计算应用中心)开发出了 Mosaic,是第一个可以图文混排的浏览器,随后又在 1995 年开发出了服务器软件 Apache,简化了 HTTP 服务器的搭建工作
同一时期,1992 年发明了 JPEG 图像格式,1995 年发明了 MP3 音乐格式
HTTP/1.0 版本在 1996 年正式发布。它在多方面增强了 0.9 版,形式上已经和我们现在的 HTTP 差别不大了,例如:
- 增加了 HEAD、POST 等新方法
- 增加了响应状态码,标记可能的错误原因;
- 引入了协议版本号概念;
- 引入了 HTTP Header(头部)的概念,让 HTTP 处理请求和相应更加灵活;
- 传输的数据不再仅限于文本
但 HTTP/1.0 并不是一个“标准”,只是记录已有实践和模式的一份参考文档,不具有实际的约束力,相当于一个“备忘录”
HTTP/1.1
网景与微软的“浏览器大战”推动了 Web 的发展,在“浏览器大战”结束之后的 1999 年,HTTP/1.1 发布了 RFC 文档,编号为 2616,成为“正式的标准”。这意味着今后互联网上所有的浏览器、服务器、网关、代理等等,只要用到 HTTP 协议,就必须严格遵守这个标准,相当于是互联网世界的一个“立法”
HTTP/1.1 的主要变更有:
- 增加了 PUT、DELETE 等新的方法;
- 增加了缓存管理和控制;
- 明确了连接管理,允许持久连接;
- 允许相应数据分块(chunked),允许传输大文件;
- 强制要求 Host 头,让互联网主机托管成为可能
HTTP/2
2015 年发布 HTTP/2,RFC 编号 7540,由 Google 推动,将自家的 SPDY 协议推上标准的宝座,称为了 HTTP/2 协议
HTTP/2 的做法充分考虑了现今互联网的现状:宽带、移动、不安全,在高度兼容 HTTP/1.1 的同时在性能上做了很大的改善,主要特点有:
- 二进制协议,不再是纯文本;
- 可发起多个请求,废弃了 1.1 里的管道;
- 使用专用算法压缩头部,减少数据传输量;
- 允许服务器主动向客户端推送数据;
- 增强了安全性,“事实上”要求加密通信
虽然 HTTP/2 推出已经好几个年头了,但因为 HTTP/1.1 实在太过经典和强势,目前普及率还比较低
HTTP/3
HTTP/2 也有队头阻塞,但它的队头阻塞是在 TCP 协议中,所以把底层协议一换,就让”更快“,简单来说,就是 HTTP/3 就是把 HTTP 底层的 TCP 协议改成了 UDP
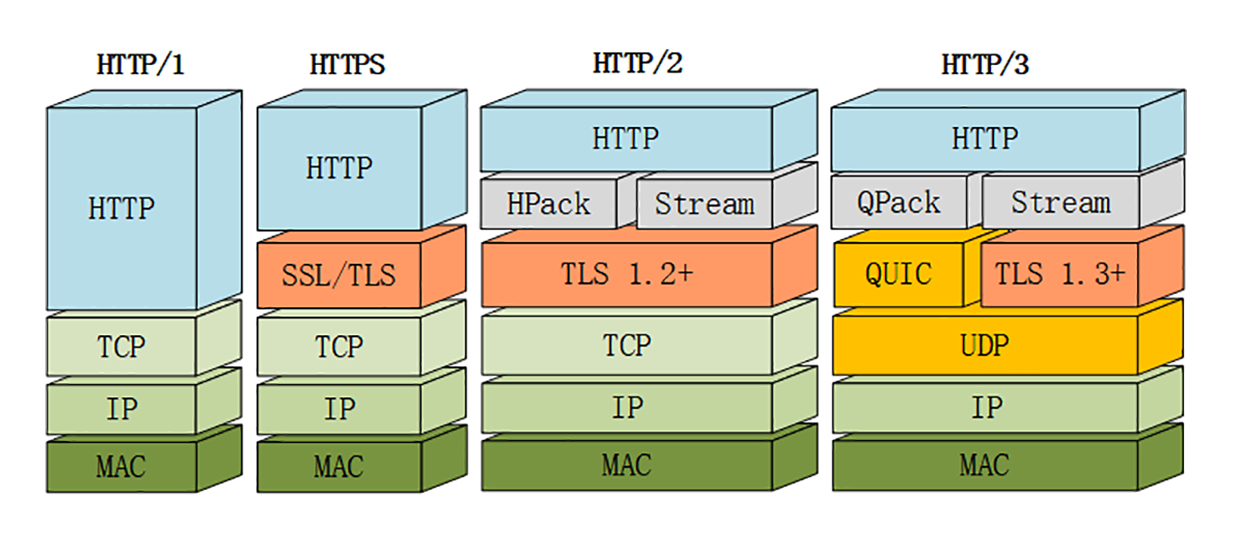
因为 UDP 是无序的,包之间没有依赖关系,所以就从根本上解决了队头阻塞
但因为 UDP 是一个简单、不可靠的传输协议,所以 Google 封装了它,在它之上加上 TCP 的那套连接管理、拥塞窗口、浏览控制等,打造了一个新时代的 TCP,即 QUIC
小结
- HTTP 协议始于三十年前蒂姆·博纳斯·李的一篇论文
- HTTP/0.9 是个简单的文本协议,只能获取文本资源;
- HTTP/1.0 确立了大部分现有使用的技术,但它不是正式标准;
- HTTP/1.1 是目前互联网上使用最广泛的协议,功能也非常完善;
- HTTP/2 基于 Google 的 SPDY 协议,注重性能改善,但普及度不高
- HTTP/3 基于 Google 的 QUIC 协议,是将来的发展方向